本次使用百度地图api获取数据,采用到的技术如下:
3.存储数据:存储至MySQL数据库
1项目描述
本项目的目标是,通过百度地图web服务api获取中国所有城市的公园数据,并获取每一个公园具体评分、描述等详细内容,最终将数据存储到MySQL数据库。
百度地图Place API(web服务api–地点检索)地址为http://lbsyun.baidu.com/index.php?title=webapi/guide/webservice-placeapi
网络爬虫除了进入网站网页爬取外还可以通过网站提供的api进行爬取,由于api是官方提供的获取数据通道,所以数据的获取没有争议,如果一个网站提供api获取数据,最好使用api进行数据获取,简单又便捷。
除了百度地图外,其他国内提供api免费获取数据的站点还有新浪微博,豆瓣电影,饿了吗,豆瓣音乐等等,国外提供api服务的有Facebook,Twitter等。除此之外,还有很多收费的api数据站点服务,包括百度 api store 和聚合数据等。其他可以搜索一下就有了。
2获取api秘钥
进入这个http://lbsyun.baidu.com/index.php?title=webapi/guide/webservice-placeapi网址后,点击右上角的登录,用自己的百度账号进行登录,登录后可以进入api控制台。(如果没有注册为开发者需要注册认证完即可),然后单击创建应用按钮。
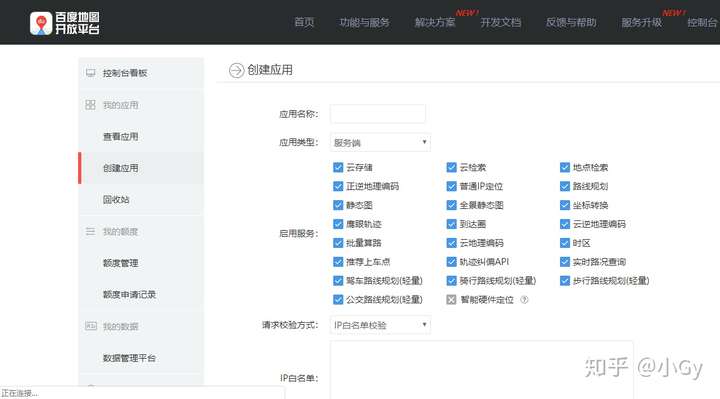
填写好应用名称,选择使用ip白名单校验方式进行校验。在ip白名单的文本框中填写0.0.0.0/0,表示不对ip做任何限制。单机提交,即可在api控制台看到自己创建的AK,就是api请求串的必填参数。
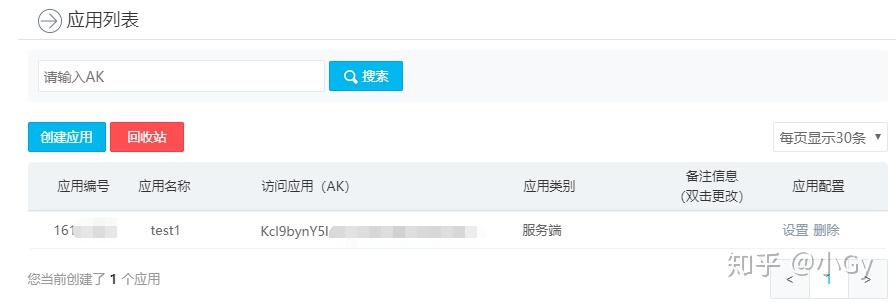
有一点注意的是,未认证(个人或企业)的情况下,每个账号一天最多只有2000次调用额,如果认证了,每个账号每天有10万次调用额。
3 项目实施
本次项目实施主要分为三步:
1.获取所有拥有公园的城市,并将数据存储到txt文本中。
2.获取所有城市的公园数据,并将数据存储到MySQL数据库中。
3.获取所有公园的详细信息,并将数据存储到MySQL数据库中。
在百度地图Place api中,如果需要获取数据,向指定URL地址发送一个get请求即可。例如,要获取数据的城市为北京,检索关键字为“ATM机”,分类偏好为银行,检索后返回10条数据,可以请求下面地址(通过 行政区划区域检索):http://api.map.baidu.com/place/v2/search?query=ATM机&tag=银行®ion=北京&output=json&ak=您的ak //GET请求
请求参数,设置如下(具体查看链接):
微信公众平台
还有其他的检索方式,这里不一一介绍了,具体可参考http://lbsyun.baidu.com/index.php?title=webapi/guide/webservice-placeapi中的服务文档。
下面尝试获取北京市的公园数据,并用json数据格式返回,代码如下:
# coding=utf-8 import requests import json \'\'\' 获取北京市的公园数据,并用json数据格式返回 \'\'\' def get_json(region): headers = { \'User-Agent\': \'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16\' } params = { \'query\': \'公园\', #检索关键字 \'region\': region, #检索行政区划区域 \'output\': \'json\', #输出格式为json \'scope\': \'2\', #检索结果详细程度。取值为1 或空,则返回基本信息;取值为2,返回检索POI详细信息 \'page_size\': 20, #单次召回POI数量,默认为10条记录,最大返回20条。 \'page_num\': 0, #分页页码,默认为0,0代表第一页,1代表第二页,以此类推。 \'ak\': \'Kcl9bynY5Icf1yGv6mQPzS7Phhkuw0Pb\' } res = requests.get(\"http://api.map.baidu.com/place/v2/search\", params=params, headers=headers) content = res.text decodejson = json.loads(content) #将已编码的 JSON 字符串解码为 Python 对象,就是python解码json对象 #return decodejson print(decodejson) get_json(\"北京市\")
输出结果为:

3.1 获取所有拥有公园的城市
接下来我们获取所有拥有公园的城市,并把数据存储到txt文本中。
在百度地图Place api,如果region的值为“全国”或则某个省份,则会返回指定区域的POI和数量。
我们可以把region设置为各个省份,进而获取各个省份各个市的公园数量。还有就是四大直辖市(北京、上海、天津、重庆)、香港特别行政区和澳门特别行政区,一个城市便是省级行政单位,因此region设置的省份不包含这些特殊省级行政单位。
# coding=utf-8
import requests
import json
\'\'\'
获取所有拥有公园的城市,并把数据存储到txt文本中
\'\'\'
def get_json(region):
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16\'
}
params = {
\'query\': \'公园\', #检索关键字
\'region\': region, #检索行政区划区域
\'output\': \'json\', #输出格式为json
\'scope\': \'2\', #检索结果详细程度。取值为1 或空,则返回基本信息;取值为2,返回检索POI详细信息
\'page_size\': 20, #单次召回POI数量,默认为10条记录,最大返回20条。
\'page_num\': 0, #分页页码,默认为0,0代表第一页,1代表第二页,以此类推。
\'ak\': \'Kcl9bynY5Icf1yGv6mQPzS7Phhkuw0Pb\'
}
res = requests.get(\"http://api.map.baidu.com/place/v2/search\", params=params, headers=headers)
content = res.text
decodejson = json.loads(content) #将已编码的 JSON 字符串解码为 Python 对象,就是python解码json对象
return decodejson
# print(decodejson)
# get_json(\"北京市\")
province_list = [\'江苏省\', \'浙江省\', \'广东省\', \'福建省\', \'山东省\', \'河南省\', \'河北省\', \'四川省\', \'辽宁省\', \'云南省\',
\'湖南省\', \'湖北省\', \'江西省\', \'安徽省\', \'山西省\', \'广西壮族自治区\', \'陕西省\', \'黑龙江省\', \'内蒙古自治区\',
\'贵州省\', \'吉林省\', \'甘肃省\', \'新疆维吾尔自治区\', \'海南省\', \'宁夏回族自治区\', \'青海省\', \'西藏自治区\']
for eachprovince in province_list:
decodejson = get_json(eachprovince)
for eachcity in decodejson[\'results\']:
city = eachcity[\'name\']
num = eachcity[\'num\']
content = \'\\t\'.join([city,str(num)])+\'\\r\\n\'
with open(\'citys_garden_num.txt\',\'a+\',encoding=\'utf-8\') as f:
f.write(content)
f.close()
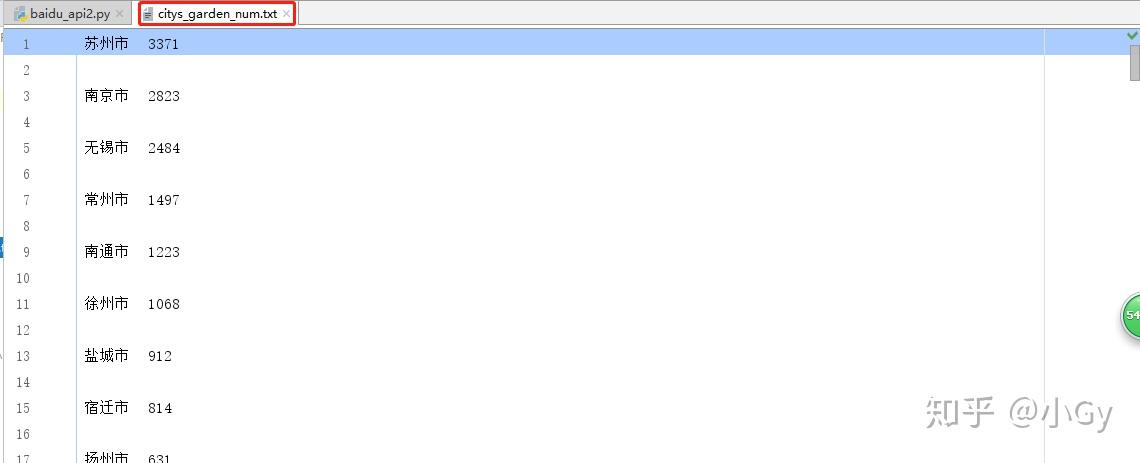
输出结果为:
接着,我们还要获取四个直辖市以及香港和澳门的数据,并把数据追加写入到citys_garden_num.txt文本中。
# coding=utf-8
import requests
import json
\'\'\'
获取所有拥有公园的城市,并把数据存储到txt文本中
\'\'\'
def get_json(region):
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16\'
}
params = {
\'query\': \'公园\', #检索关键字
\'region\': region, #检索行政区划区域
\'output\': \'json\', #输出格式为json
\'scope\': \'2\', #检索结果详细程度。取值为1 或空,则返回基本信息;取值为2,返回检索POI详细信息
\'page_size\': 20, #单次召回POI数量,默认为10条记录,最大返回20条。
\'page_num\': 0, #分页页码,默认为0,0代表第一页,1代表第二页,以此类推。
\'ak\': \'Kcl9bynY5Icf1yGv6mQPzS7Phhkuw0Pb\'
}
res = requests.get(\"http://api.map.baidu.com/place/v2/search\", params=params, headers=headers)
content = res.text
decodejson = json.loads(content) #将已编码的 JSON 字符串解码为 Python 对象,就是python解码json对象
return decodejson
# print(decodejson)
# get_json(\"北京市\")
decodejson = get_json(\'全国\')
six_cities_list = [\'北京市\',\'上海市\',\'重庆市\',\'天津市\',\'香港特别行政区\',\'澳门特别行政区\',]
for eachprovince in decodejson[\'results\']:
city = eachprovince[\'name\']
num = eachprovince[\'num\']
if city in six_cities_list:
content = \'\\t\'.join([city, str(num)]) + \'\\r\\n\'
with open(\'citys_garden_num.txt\', \"a+\", encoding=\'utf-8\') as f:
f.write(content)
f.close()
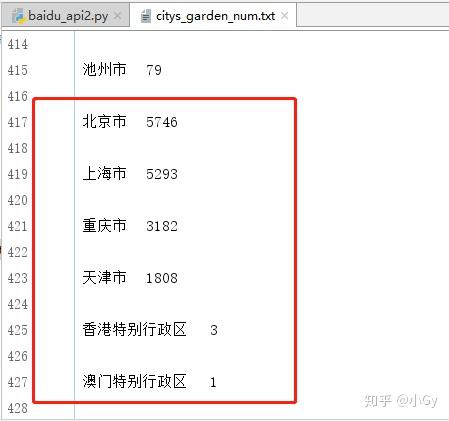
输出结果为:
3.2 获取所有城市的公园数据
这次计划把公园的数据存储在MySQL数据库中,所以我们必须先创建一个badiumap数据库,用来存放所有公园爬去的数据。
创建一个数据库,语句为:create database baidumap;
当然也可以使用可视化工具创建数据库与完成一系列操作,如建表等。
然后就是建表了,在baidumap数据库中创建一个city表,用于存放所有城市的公园数据,公园的变量有:city,park,location_lng等等。这些变量就是第一部分测试的返回results中的数据,根据建立即可。
其中,为了避免数据存储重复,公园的详细信息会存储到另一个表中。
我们使用python的mysqlclient库来操作MySQL数据库,在baidumap数据库中建立city表。
# coding=utf-8
import MySQLdb
conn = MySQLdb.connect(host=\'localhost\',user=\'root\',password=\'123456\',port=3306,db=\'baidumap\')
cur=conn.cursor()
sql = \"\"\"CREATE TABLE city (
id INT NOT NULL AUTO_INCREMENT,
city VARCHAR(200) NOT NULL,
park VARCHAR(200) NOT NULL,
location_lat FLOAT,
location_lng FLOAT,
address VARCHAR(200),
street_id VARCHAR(200),
uid VARCHAR(200),
created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (id)
);\"\"\"
cur.execute(sql)
cur.close()
conn.commit()
conn.close()
接下来,爬取每个城市的公园数据,保存到city中。
# coding=utf-8 import requests import json import MySQLdb \'\'\' 获取所有城市的公园数据 \'\'\'
conn = MySQLdb.connect(host=\'localhost\',user=\'root\',password=\'123456\',port=3306,db=\'baidumap\',charset=\"utf-8\")
cur=conn.cursor()
# sql = \"\"\"CREATE TABLE city (
# id INT NOT NULL AUTO_INCREMENT,
# city VARCHAR(200) NOT NULL,
# park VARCHAR(200) NOT NULL,
# location_lat FLOAT,
# location_lng FLOAT,
# address VARCHAR(200),
# street_id VARCHAR(200),
# uid VARCHAR(200),
# created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
# PRIMARY KEY (id)
# );\"\"\"
# cur.execute(sql)
# cur.close()
# conn.commit()
# conn.close()
def get_json(region,page_num):
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16\'
}
params = {
\'query\': \'公园\', #检索关键字
\'region\': region, #检索行政区划区域
\'output\': \'json\', #输出格式为json
\'scope\': \'2\', #检索结果详细程度。取值为1 或空,则返回基本信息;取值为2,返回检索POI详细信息
\'page_size\': 20, #单次召回POI数量,默认为10条记录,最大返回20条。
\'page_num\': 0, #分页页码,默认为0,0代表第一页,1代表第二页,以此类推。
\'ak\': \'Kcl9bynY5Icf1yGv6mQPzS7Phhkuw0Pb\'
}
res = requests.get(\"http://api.map.baidu.com/place/v2/search\", params=params, headers=headers)
content = res.text
decodejson = json.loads(content) #将已编码的 JSON 字符串解码为 Python 对象,就是python解码json对象
return decodejson
city_list=[]
with open(\'citys_garden_num.txt\',\'r\',encoding=\'utf-8\') as f:
# print(f.read())
for eachLine in f:
if eachLine !=\"\" and eachLine !=\"\\n\":
fields = eachLine.split(\"\\t\")
city=fields[0]
city_list.append(city)
#print(city_list)
for eachcity in city_list:
not_last_page = True
page_num = 0
while not_last_page:
decodejson = get_json(eachcity,page_num)
print(eachcity,page_num)
if decodejson[\'results\']:
for eachone in decodejson[\'results\']:
try:
park = eachone[\'name\']
except:
park = None
try:
location_lat = eachone[\'location\'][\'lat\']
except:
location_lat = None
try:
location_lng = eachone[\'location\'][\'lng\']
except:
location_lng = None
try:
address = eachone[\'address\']
except:
address = None
try:
street_id = eachone[\'street_id\']
except:
street_id = None
try:
uid = eachone[\'uid\']
except:
uid = None
sql = \"\"\"INSERT INTO baidumap.city
(city, park, location_lat, location_lng, address, street_id, uid)
VALUES
(%s, %s, %s, %s, %s, %s, %s);\"\"\"
cur.execute(sql,(eachcity, park, location_lat, location_lng, address, street_id, uid,))
conn.commit()
page_num += 1
else:
not_last_page = False
cur.close()
conn.close()
在爬取过程中,遇到一个错误:

解决办法:

在上述代码中,首先从txt文件中获取城市列表,并加入city_list列表中,然后使用循环对每一个城市,每一页进行抓取,将获取数据用insert的方法插入到baidumap数据库的city表中,注意到我是用了try…except方法,主要是因为有些字段的值会空或则丢失,如有些公园没有街道id的,没有就赋予none值,防止程序保存。
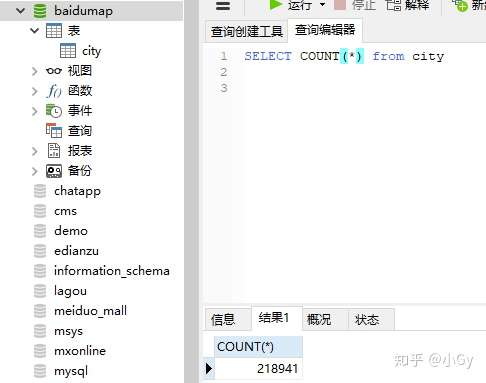
共爬取了218941个公园信息,大概用了几分钟。
3.3 获取所有公园的详细信息
上面已经把所有城市的公园数据存储到city表中了。但是这些数据属于粗略的数据,接下来我们通过报读地图的Place详细检索服务获取每一个公园的详细信息。
例如,查询南京玄武湖公园的详细信息,我们需要知道玄武湖公园的uid,然后在请求地址中加上uid进行请求。
下面介绍下地点详细检索服务:
请求地址
http://api.map.baidu.com/place/v2/detail?uid=435d7aea036e54355abbbcc8&output=json&scope=2&ak=您的密钥 //GET请求
请求参数以及返回参数(行政区划区域检索、圆形区域检索、矩形区域检索、地点详情检索)(详细见下链接):
微信公众平台
下面我们开始操作,在MySQL数据库中的baidumap中新建一个park表,用于存储公园详细信息。
创建park表代码如下:
# coding=utf-8
import requests
import json
import MySQLdb
\'\'\'
获取所有公园的详细信息
\'\'\'
conn = MySQLdb.connect(host=\'localhost\',user=\'root\',password=\'123456\',port=3306,db=\'baidumap\',charset=\"utf8\")
cur=conn.cursor()
#创建park表
sql = \"\"\"CREATE TABLE park (
id INT NOT NULL AUTO_INCREMENT,
park VARCHAR(200) NOT NULL,
location_lat FLOAT,
location_lng FLOAT,
address VARCHAR(200),
street_id VARCHAR(200),
telephone VARCHAR(200),
detail INT,
uid VARCHAR(200),
tag VARCHAR(200),
type VARCHAR(200),
detail_url VARCHAR(800),
price INT,
overall_rating FLOAT,
image_num INT,
comment_num INT,
shop_hours VARCHAR(800),
alias VARCHAR(800),
keyword VARCHAR(800),
scope_type VARCHAR(200),
scope_grade VARCHAR(200),
description VARCHAR(9000),
created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (id)
);\"\"\"
cur.execute(sql)
cur.close()
conn.commit()
conn.close()
创建好park表之后,我们可以获取公园的详细信息了,代码如下:
# coding=utf-8
import requests
import json
import MySQLdb
\'\'\'
获取所有公园的详细信息
\'\'\'
conn = MySQLdb.connect(host=\'localhost\',user=\'root\',password=\'123456\',port=3306,db=\'baidumap\',charset=\"utf8\")
cur=conn.cursor()
#创建park表
# sql = \"\"\"CREATE TABLE park (
# id INT NOT NULL AUTO_INCREMENT,
# park VARCHAR(200) NOT NULL,
# location_lat FLOAT,
# location_lng FLOAT,
# address VARCHAR(200),
# street_id VARCHAR(200),
# telephone VARCHAR(200),
# detail INT,
# uid VARCHAR(200),
# tag VARCHAR(200),
# type VARCHAR(200),
# detail_url VARCHAR(800),
# price INT,
# overall_rating FLOAT,
# image_num INT,
# comment_num INT,
# shop_hours VARCHAR(800),
# alias VARCHAR(800),
# keyword VARCHAR(800),
# scope_type VARCHAR(200),
# scope_grade VARCHAR(200),
# description VARCHAR(9000),
# created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
# PRIMARY KEY (id)
# );\"\"\"
sql=\"select uid from baidumap.city where id >0;\"
cur.execute(sql)
conn.commit()
results=cur.fetchall() #将返回所有结果,返回二维元组,如((\'id\',\'name\'),(\'id\',\'name\')),
def get_json(uid):
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16\'
}
params = {
\'uid\': uid,
\'output\': \'json\', #输出格式为json
\'scope\': \'2\', #检索结果详细程度。取值为1 或空,则返回基本信息;取值为2,返回检索POI详细信息
\'ak\': \'Kcl9bynY5Icf1yGv6mQPzS7Phhkuw0Pb\'
}
res = requests.get(\"http://api.map.baidu.com/place/v2/detail\", params=params, headers=headers)
content = res.text
decodejson = json.loads(content) #将已编码的 JSON 字符串解码为 Python 对象,就是python解码json对象
return decodejson
for row in results:
uid = row[0]
decodejson = get_json(uid)
print (uid)
while \'results\' in decodejson:
info = decodejson[\'result\']
try:
park = info[\'name\']
except:
park = None
try:
location_lat = info[\'location\'][\'lat\']
except:
location_lat = None
try:
location_lng = info[\'location\'][\'lng\']
except:
location_lng = None
try:
address = info[\'address\']
except:
address = None
try:
street_id = info[\'street_id\']
except:
street_id = None
try:
telephone = info[\'telephone\']
except:
telephone = None
try:
detail = info[\'detail\']
except:
detail = None
try:
tag = info[\'detail_info\'][\'tag\']
except:
tag = None
try:
detail_url = info[\'detail_info\'][\'detail_url\']
except:
detail_url = None
try:
type = info[\'detail_info\'][\'type\']
except:
type = None
try:
overall_rating = info[\'detail_info\'][\'overall_rating\']
except:
overall_rating = None
try:
image_num = info[\'detail_info\'][\'image_num\']
except:
image_num = None
try:
comment_num = info[\'detail_info\'][\'comment_num\']
except:
comment_num = None
try:
key_words = \'\'
key_words_list = info[\'detail_info\'][\'di_review_keyword\']
for eachone in key_words_list:
key_words = key_words + eachone[\'keyword\'] + \'/\'
except:
key_words = None
try:
shop_hours = info[\'detail_info\'][\'shop_hours\']
except:
shop_hours = None
try:
alias = info[\'detail_info\'][\'alias\']
except:
alias = None
try:
scope_type = info[\'detail_info\'][\'scope_type\']
except:
scope_type = None
try:
scope_grade = info[\'detail_info\'][\'scope_grade\']
except:
scope_grade = None
try:
description = info[\'detail_info\'][\'description\']
except:
description = None
sql = \"\"\"INSERT INTO baidumap.park
(park, location_lat, location_lng, address, street_id, uid, telephone, detail, tag, detail_url, type, overall_rating, image_num,
comment_num, keyword, shop_hours, alias, scope_type, scope_grade, description)
VALUES
(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s);\"\"\"
cur.execute(sql, (park, location_lat, location_lng, address, street_id, uid, telephone, detail, tag, detail_url,
type, overall_rating, image_num, comment_num, key_words, shop_hours, alias, scope_type, scope_grade, description,))
conn.commit()
cur.close()
conn.close()
以上便完成了所有公园详细信息的抓取并存入数据库baidumap的park表中。
最后,说一下百度地图api提供了相当丰富的资源数据,如房地产,旅馆,游乐园等等很多,有需要你们可以自己去尝试抓取。
参考资料:
学习《Python网络爬虫从入门到实践》的记录 作者:唐松 陈智铨 出版社:机械工业出版社
转载至:https://zhuanlan.zhihu.com/p/73712621





